目次
【SEO】「シグナル(評価要因)は正規URLに転送されて統合される」
「rel="canonical"」についての情報です。
グーグルのURL正規化はこんなふうに処理されていた
グーグルのURL正規化の処理方法や、noindexとrobots.txtが正規化には向かないことを、グーグルのジョン・ミューラー氏が詳細に説明した。
きっかけは、redditのSEO掲示板に書き込まれた次のような質問だ。この質問者はSEOに詳しくないようで意味不明な質問だ。
質問です:
noindexが記述されているページに自己参照のrel="canonical"を記述している場合、グーグルはそのrel="canonical"を無視するか?
rel="canonical"と比較したときの、noindexの不利な点は何か?
しかし親切な回答者たちは、その意図を汲んで解説していった。その流れでジョン・ミューラー氏は次のように述べている。
大まかに言えば、シグナル(評価要因)は正規URLに転送されて統合される。
たとえば、次のような状況があるとする:
グーグルから見て、サイト内にある2つのURLの内容が同一に見える
優先するURLをサイト管理者が明確に示している
この場合グーグルは、2つのURLを別々のページとして扱うのではなく、1つのURL(通常は評価が高いURL)として統合処理しようとする。優先するURLをグーグルに伝えるには、次のような手段がある:
リダイレクト
rel="canonical"
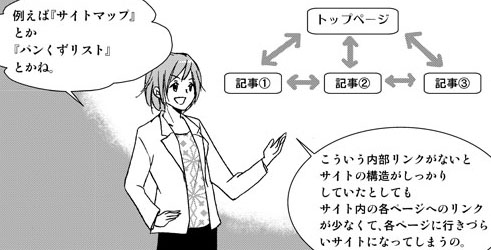
内部リンク
外部リンク
サイトマップ
hreflang
こうしたシグナルが一貫していればいるほど、グーグルはそれらの情報を使ってより適切な正規URLを選べる(そして、選択された正規URLにすべてのシグナルを転送できる)。一方で、次のような手法は、一般的には、URL正規化の明確な指示にはならない。:
(単独の)noindex
robots.txtによるクロール拒否
ページにnoindexを指定するだけでは、「他のURLと統合し、シグナルを正規URLに転送してほしい」という指示にはならない。robots.txtのクロール拒否はさらに扱いにくい。グーグルはページをクロールできないので、そのページにサイト内の他のページと同様の内容があるかどうかすらわからない。そうなると、正規化なんてできるはずがない。
「noindexとrel="canonical"を併用すべきではない」とグーグルは推奨しているが、その背景にはこうしたことがある。
noindexとrel="canonical"が同じページに記述されていることは、グーグルにとっては矛盾した状況になるからだ。そうした状況があったらグーグルは、一般的にはnoindexよりもrel="canonical"を優先して処理するだろう。
しかし、そうした「矛盾した情報」をグーグルに示して「あとは任せた」という状況にするのは、あなたがグーグルに提供できる情報の重要度を自ら下げることになる点は理解しておいてほしい。
SEOで重要なのは、あなたの指示をグーグルに適切に伝えることなのだから。
最初の質問は忘れていいので、重要な点をまとめよう。
同じページが複数のURLで公開されている時は、1つのURLにグーグルは統合(正規化)しようとする
正規化のためには、リダイレクトやリンク、サイトマップなどさまざまな要素が利用される
正規URLを制御するために、サイト管理者は一貫した情報をグーグルに伝えるべき
一般的には、noindexもrobots.txtも正規化には役立たない
rel="canonical"とnoindexを1ページ内に両方記述するのは矛盾した指示になるので、避けるべきである
SEOコンサルタントの感想
1つのURLに決めてそれを統一することですね。

SEO・IT漫画「ウェブマブ!」

マンガボックスインディーズ
LINEマンガインディーズ
少年ジャンプルーキー
あしたのヤングジャンプ
DAYS NEO -デイズ ネオ-
マガジンデビュー
マンガハック
SEOまんが